안녕하세요. 오늘은 자바의 동기화에 대해서 알아보려고 합니다.
자바의 동기화에 대해서 알려면, 모니터, synchronized 키워드, wait() 메서드, notify() 메서드를 잘 이해해야 합니다.
모니터
모니터란?
자바는 모니터를 이용해서 동기화를 지원합니다. 이 모니터는 자바의 각 객체마다 하나씩 소유하고 있습니다.
그렇다면, 모니터란 뭘까요? 모니터는 뮤텍스, 세마포어 같은 동기화 방식의 추상화된 동기화 방식이라고 할 수 있습니다.
간단하게 뮤텍스/세마포어의 방식을 알아볼까요?
public void run() {
lock()
// do something
unlock()
}이런 방식으로 임계 영역을 접근하기 전에 명시적으로 잠금과 해제를 선언하는 방식입니다.
반면, 모니터의 경우는 아래와 같은 방식입니다.
public void run() {
// 아래 lock 블록에 포함된 코드는 lock을 건 상태로 진행하는 것
lock {
// do something
}
}명시적으로 잠금과 해제하는 부분이 없는 것을 볼 수 있습니다. lock 블록에 포함된 영역에 자동으로 잠금과 해제를 해주는 방식이죠.
자바에서 모니터 사용(synchronized 키워드)
위에서는 lock이라는 키워드를 통해 임계 영역을 표시했습니다. 자바에서는 어떻게 할까요?
바로 synchronized라는 키워드를 사용합니다.
public void run() {
synchronized {
// do something
}
}
// or
public synchronized void run() {
// do something
}이렇게 두 가지 방식으로 사용할 수 있습니다.
synchronized 블록을 선언하거나, 아예 메서드에 synchronized 키워드를 붙이는 방식입니다.
synchronized 블록 내부에서만 사용할 수 있는 메서드도 있습니다. 바로 wait(), notify() 메서드입니다.
wait()
해당 객체를 사용하고 있는 스레드가, 대기 상태로 변경되도록 합니다.
notify()
해당 클래스에 의해 대기 상태로 변경된 스레드 중 하나를 깨웁니다.
이때, 여러 개의 스레드가 대기 상태라면 JVM이 판단해서 하나의 스레드를 깨웁니다. 어느 스레드가 선택될지는 알 수 업습니다.
synchronized 예제
synchronized 키워드는 주로 객체의 내부 상태를 변경할 때 레이스 컨디션을 방지하고자 사용합니다.
두 개의 스레드가 하나의 객체의 상태를 변경한다고 가정해 봅시다. 한 스레드는 1을 더하는 행위를 1000번 하고, 다른 스레드는 1을 빼는 행위를 1000번 합니다. 모든 행위가 종료되면 0이 결과로 나오는 것을 기대하고 있습니다.
class Data {
private int count = 0;
public void increment() {
count++;
}
public void decrement() {
count--;
}
public int getCount() {
return count;
}
}
public class Main {
public static void main(String[] args) {
Data data = new Data();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
data.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
data.decrement();
}
});
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(data.getCount());
}
}이 코드의 경우 0이 아닌 다른 결과를 보여줍니다. 또한 일관된 결과를 보여주지 않습니다.
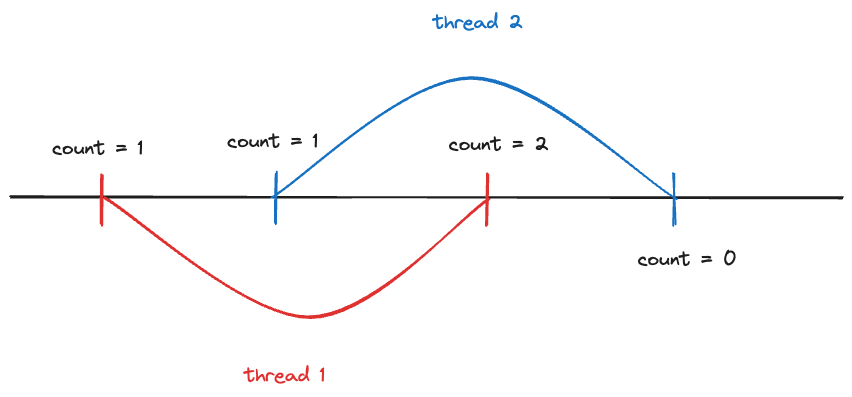
왜냐하면, 레이스 컨디션이 발생했기 때문입니다.

위 사진과 같은 현상이 계속해서 발생하기 때문에 기대한 값이 결과로 나오지 않습니다.
이 문제는 변수를 조작하는 부분은 임계 영역으로 지정하고, 한 번에 하나의 스레드만 접근하도록 하면 문제를 해결됩니다.
class Data {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized void decrement() {
count--;
}
public synchronized int getCount() {
return count;
}
}
public class Main {
public static void main(String[] args) {
Data data = new Data();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
data.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
data.decrement();
}
});
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(data.getCount());
}
}이 코드는 항상 0이라는 결과를 출력합니다. Data의 메서드를 보시면 모두 synchronized 키워드가 붙어있는 것을 알 수 있습니다.
그러므로 한 번에 하나의 스레드만 count 변수에 접근할 수 있게 됩니다.
wait(), notify() 예제
이런 메서드들은 데이터를 생성하고, 소비하는 경우에 사용할 수 있습니다.
생성자 입장에서는 생성하다가, 용량이 가득 차면 생성을 중지하고, 소비자가 데이터를 소비할 때까지 기다려야 합니다.(wait)
그리고 생성자는 어떠한 데이터를 생성하는 순간 대기하고 있던 소비자를 깨워야 합니다.(notify) 그래야 소비를 해서 용량이 가득 차지 않을 테니까요.
소비자 입장에서는 소비하려고 하는데 아무 데이터도 생성되지 않으면 대기해야 합니다.(wait)
그리고 소비하고 나서 생성자에게 데이터를 소비했으니 데이터를 생성하라고 알려줘야 합니다.(notify)
이를 잘 설명할 수 있는 예제는 프린터입니다.
- 프린터는 한 번에 하나의 문서만을 출력할 수 있음
- 프린터는 출력할 문서를 3개까지 저장할 수 있음
- 출력 요청이 한 번에 3개가 초과해서 데이터가 누락되면 안 됨
import java.util.LinkedList;
import java.util.Queue;
class PrintQueue {
private final int MAX_SIZE = 3;
private final Queue<String> documents = new LinkedList<>();
public synchronized void addDocument(String document) throws InterruptedException {
if (documents.size() >= MAX_SIZE) {
wait();
}
documents.add(document);
System.out.println("Added: " + document);
notify();
}
public synchronized void printDocument() throws InterruptedException {
if (documents.isEmpty()){
wait();
}
System.out.println("Printed: " + documents.poll());
notify();
}
}
class User implements Runnable {
private final PrintQueue printQueue;
public User(PrintQueue printQueue) {
this.printQueue = printQueue;
}
@Override
public void run() {
String[] documentsToAdd = {"Doc1", "Doc2", "Doc3", "Doc4", "Doc5", "Doc6", "Doc7", "Doc8", "Doc9", "Doc10"};
for (String doc : documentsToAdd) {
try {
printQueue.addDocument(doc);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
}
class Printer implements Runnable {
private final PrintQueue printQueue;
public Printer(PrintQueue printQueue) {
this.printQueue = printQueue;
}
@Override
public void run() {
try {
for (int i = 0; i < 10; i++) {
printQueue.printDocument();
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
public class Main {
public static void main(String[] args) {
PrintQueue printQueue = new PrintQueue();
Thread producerThread = new Thread(new User(printQueue));
Thread consumerThread = new Thread(new Printer(printQueue));
producerThread.start();
consumerThread.start();
}
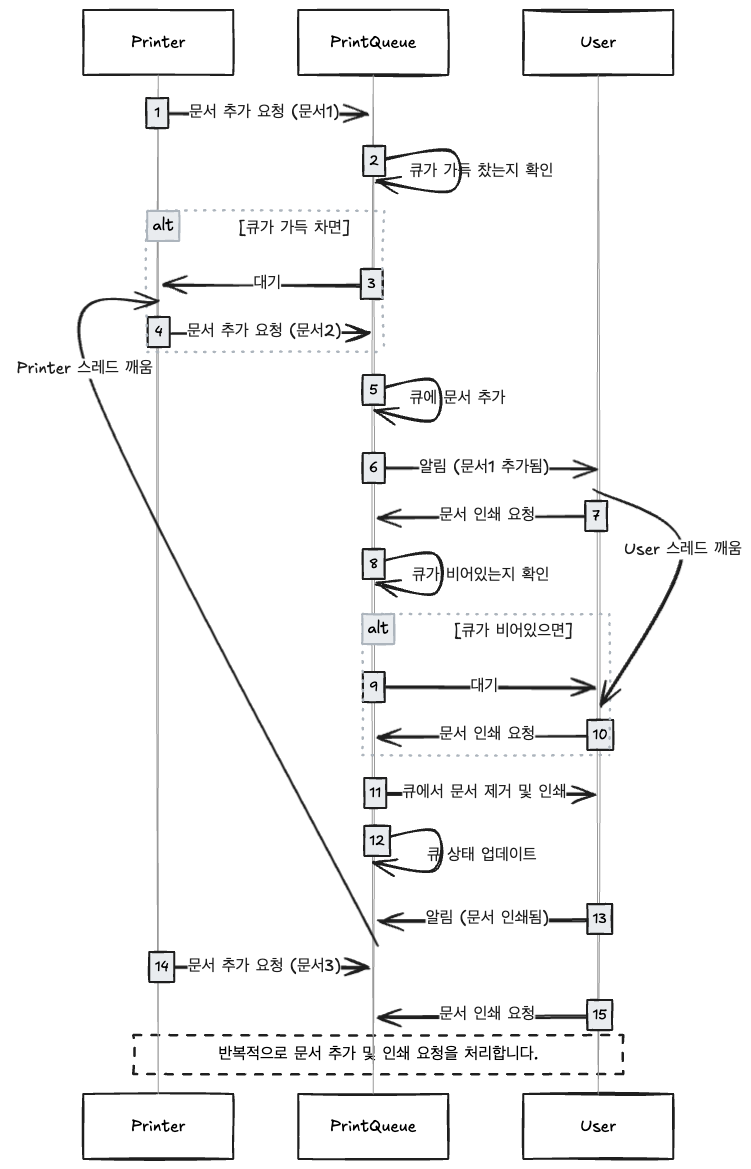
}User 스레드가 생성자, Printer 스레드가 소비자, PrinterQueue가 두 스레드에서 사용하는 객체입니다.
자세한 시퀀스는 아래와 같습니다.
마무리
스레드를 적극적으로 사용하는 방식의 경우 이해하기가 어려운 것 같습니다. 비동기 방식, 동기화 방법 등과 같은 것들이 그러합니다.
하지만 어떻게든 이해하고 나면 실무에서 사용할 때 막힘없이 진행할 수 있는 것 같다고 느낍니다.
저 또한 한 번씩 헷갈리는 면이 있어서 이번 기회에 동기화를 정리해 보았습니다. 앞으로도 계속해서 헷갈리지 않도록 잘 정리해 두어야겠습니다.
'JVM > Java' 카테고리의 다른 글
| Java Virtual Thread 사용하는 방법 (0) | 2025.02.03 |
|---|---|
| Java의 Virtual Thread에 대해서(JEP444) (0) | 2025.02.02 |
| Java에서 MessageDigest를 이용해서 해시코드 생성하기 (SHA-256, SHA-512, MD5) (0) | 2025.02.02 |